总结一下这几个月的面试经历中被问到的问题,虽说问得都很浅,但是,问深了我也不会呀!
C++相关
Q: std::vector push_back 的复杂度是多少?
A: O(1), amortized constant.
Q: vector从1到n push n个元素,假设发生扩容时按两倍增长,写出复杂度关于n的表达式?
A: 不会。
假设第一次只分配一个元素的空间。那么发生扩容的点依次如下:
每次扩容都会copy之前内存中的所有元素,所以总共发生的拷贝次数为:
注意这里共有$\lfloor \log_2 n \rfloor$项相加,于是有
加上push_back操作的次数n,所以有
Q: 对于一个vector容器,删除元素后迭代器会失效吗?
A: 对于删除给定元素前的迭代器不会失效,被删除元素之后的迭代器全部失效。
向容器添加元素后:
- 如果容器是vector或string,且存储空间重新分配,则指向容器的迭代器、指针和引用都会失效。如果存储空间未重新分配,指向插入位置之前的迭代器、指针和引用仍有效,但指向插入位置之后元素的迭代器、指针和引用将会失效。
- 对于deque,插入到除首尾元素以外的任何位置都会导致迭代器、指针和引用失效。如果在首尾位置添加元素,迭代器会失效,但指向存在元素的指针和引用不会失效。
- 对于list和forward_list,指向容器的迭代器(包括尾后迭代器和首前迭代)、指针和引用都有效。
当我们从一个容器中删除元素后,指向被删除元素的迭代器、指针和引用会失效,这应该不会令人惊讶。毕竟,这些元素已经被销毁了。当我们删除一个元素后:
- 对于list和forward_list,指向容器其他位置的迭代器(包括尾后和首前)、引用和指针仍有效。
- 对于deque,如果在首尾之外的任何位置删除元素指向被删除元素外其他元素的迭代器、引用和指针也会失效。如果是删除deque的尾元素,则尾后迭代器也会失效,但其他迭代器、引用和指针不受影响;如果是删除首元素,这些也不会受影响。
- 对于vector和string,指向被删除元素之前的元素迭代器、引用和指针仍有效。注意:当我们删除元素时,尾后迭代器总是会失效。
──《C++ Primer》
关于迭代器失效的问题,另参阅:https://blog.csdn.net/lujiandong1/article/details/49872763
Q: 对于使用hash函数组织的unordered_map,对于给定的hash函数,假设我总能构造一个集合,使得该集合内所有元素的hash值相同,即该集合内所有的key都映射到一个桶内。这种问题该如何解决?
A: 不会。
可以使用两个hash函数,例如h1和h2,然后将同一个key的hash值用某种方式连接起来,以此定义一个新的复杂hash函数。对于这个函数,碰撞的概率将会非常小,因此可以认为你设计不出这样的集合,使得集合内的元素都发生碰撞。
Q: new/delete和malloc/free有什么区别?
A: new/delete在C++中是运算符,但malloc/free是继承自C的内存管理函数。malloc只负责开辟指定大小的内存,并不负责初始化,而new及开辟内存,也会构造对象,如果要为自定义的类型申请动态内存,则必须使用new,new一个类型会调用该类型的构造函数。而delete和free的区别也是类似,delete调用类的析构函数,然后在释放内存,free仅释放内存。
Q: 以下调用哪个函数?1
2
3
4
5
6
7
8
9
10
11
12class base {
public:
virtual void fun(int a) { cout << a << endl; }
};
class derived : public base {
public:
void fun(int b) { cout << "derived" << endl; }
};
base* pb = new derived();
pb->fun(3);
A: derived. 虚函数的动态绑定,根据运行时类型调用对应的版本,虽然是基类指针,但实际上是派生类对象,所以调用派生类中的函数。动态绑定是C++支持多态的根本原因。关于动态绑定,参见:here.
另外,定义虚函数会增加空间开销,一旦定义了虚函数,就会生成虚函数表和虚指针,动态绑定实际上是通过查表来确定具体调用哪个版本的函数。另外构造函数不能声明为虚函数,析构函数可以,但析构函数不能声明为纯虚函数。
Q: 重载(overload)和重写(override)有什么区别?
A: 重载指函数签名(函数原型)不同的两个函数名字相同,重写是指子类覆盖(重写)基类的方法,签名必须相同。注意,返回值不算函数签名,const算重载!
另外,还涉及到隐藏的概念。所谓隐藏,其实就是子作用域如果出现和父作用域相同的名字,那么父作用域的该名字在子作用域下被隐藏,不可见,因为被子作用域同名覆盖掉了。派生类的成员将隐藏基类同名成员。请看下例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
using namespace std;
class Base {
public:
virtual void f(int x) { cout << "Base::f(int)" << endl; }
void g(float x) { cout << "Base::g(float)" << endl; }
};
class Derived : public Base {
public:
void f(float x) { cout << "Derived::f(float)" << endl; }
void g(float x) { cout << "Derived::g(float)" << endl; }
void g(int x) { cout << "Derived::g(int)" << endl; }
};
// test
int main()
{
Derived dobj;
Base* pd = &dobj;
pd->f(3); // Base::f(int)
pd->g(3.3f); // Base::g(float)
dobj.f(3.3f); // Derived::f(float)
dobj.g(3.3f); // Derived::g(float)
dobj.g(3); // Derived::g(int)
return 0;
}
子类中g发生了重载。而基类指针调用f时,发现是虚函数,会去查表(发生动态绑定),但子类中并没有相应的重写(override),子类中的f仅仅是另一个函数,所以查表得知还是调用基类的f; 基类指针调用g时,发现不是虚函数,直接调用基类的g. 此间,子类的两个g对基类的g都是隐藏!
算法相关
Q: 从一个数组中删除一个元素,复杂度是多少?如果不关心索引和值的对应关系。
A: O(1), 将要删除的元素与最后一个元素互换,将数组的长度减一。
注意:这里他说不关心数组的索引和值的对应关系。连续存储就是数组,只不过先前通过索引i获得的值,并不一定和删除后通过索引i获得的值相同。我答的是O(n),因为要删除一个元素,还得将删除元素之后的元素前移一位,这样才是我理解的删除的语义。但是面试官说不关心索引与值的对应关系,那么假设数组长度为n,删除元素位置为i,在互换A[i]和A[n]之后,删除后数组的A[i]变成了原先的A[n], 但一般认为删除后A[i]应该是原先的A[i+1], 这就是他说的不关心索引和值的对应,和我所理解的不一样。
Q: 生成50个[0, 50)间的随机整数,构成一个序列,要求不能重复?
A: 用一个长度为50的数组用作map,初始化全为0. 然后使用随机数发生器生成[0, 50)之间的整数,并在map对应索引位置+1. 依次生成随机整数,且判断其索引对应的值是否为0,等于0说明还未生成过,等于1说明已经生成过,应该换一个。但是这样不能保证收敛,也许它永远生成不满50个随机整数。
其实有O(n)的解法,延承自上一问。设有一副扑克牌,共50张,你怎样将它随机地分给排成一列的50个人?很简单,每次随机抽出一张给一个人,抽完了,也就分完了。现在你有一个随机数发生器,每次随机生成一个索引,你抽出该索引位置的牌(从数组中删除该元素),这个操作等价与将该索引的元素与数组最后一个元素互换。下一次,从[0, 49)里随机生成一个索引,纵然该索引与之前的可能一样,但对应位置的牌已经换了,所以不会抽出重复的牌。如此反复,抽完为止。这样你每删除一个元素的复杂度是O(1), 所以总共的复杂度就是O(n).
机器学习相关
Q: K-均值聚类中k如何选取,评价指标,他很不稳定,如何让它稳定一些。
评价指标:类间相似度低,类内相似度高。K-means的稳定性较差,可能每次随机选取的初始聚类中心不一样,而导致聚类的效果不一样。从某种程度上来说,K-means对数据较为敏感,无法识别离群点。传统聚类采用的距离度量通常为欧式距离,Kernel k-means将所有样本映射到另外一个特征空间中再进行聚类,就有可能改善聚类效果。
一种改进:K-means++,它的思想是在已经选定n个聚类中心后,选取第n+1个聚类中心时:距离当前n个聚类中心越远的点会有更高的概率被选为第n+1个聚类中心。在选取第一个聚类中心时同样使用随机的方法,这个改单简单有效。
另外,一个很重要的问题,K的值如何选取?在低维度时,可以将数据画出来看大致有几个类,而在面对高维和复杂数据时,这种方法难以使用。关于K的选取:ISODATA,迭代自组织数据分析法,它的思想是:当属与某个类别的样本数量过少时就把该类别去除;当属与某个类别的样本数量过多时,分散程度较大时,将该类别分裂为两个子类。
Q: 正则化如何克服过拟合?背后的原理是什么?
正则化控制模型的复杂度。正则系数越大,模型拟合能力越差(偏差大,方差小),复杂度越低,一定程度上克服了过拟合。考虑正则系数从小变大,一开始偏差较小,方差较大。因为模型足够复杂,可以很好的学到数据特征,但也容易过拟合,对特定的数据集很敏感,也许换一个数据集就会是不一样的结果,此时已经发生了过拟合。随着正则系数不断变大,偏差也跟着增加,但方差会随之减小,因为正则项事实上限制了模型的拟合能力,降低了模型的复杂度。牺牲了偏差(变大),换取了方差(变小)。而在有限的训练数据集上,方差过大就意味着过拟合,意味着模型对数据集敏感。这不是我们想要的。整个过程的泛化误差先减小(方差减小)后增大(偏差增大),先是方差主导,后是偏差主导。最佳的正则系数应该对应着最小的泛化误差。详见PRML p.151
Q: 有没有接触过其他的网络模型,CNN,RNN等?
没有。
Q: vae是生成网络吗?可不可以和infogan结合?了解一下vae?
是。
纽劢面经
- random forest 需要对特征做什么处理吗?
- 常用的特征选择方法有哪些?
- 主成分分析做特征选择有哪些缺点?
- l1 regularization 也可以做特征选择?
- 特征有离散有连续该怎么处理? one-hot encoding
牛客网C++笔记
原地址:https://www.nowcoder.com/discuss/164721?type=0&order=0&pos=16&page=0
Q:说一下static关键字的作用?
A:static可以用来声明静态变量或函数。静态变量存储在静态内存中。直到程序结束才被释放。一般程序有三块内存:静态内存、动态内存(堆内存)、栈内存(局部变量)。需要注意的是,即使在函数内部声明的静态变量,也是放在静态内存中的,静态变量具有静态生命周期。static可用于修饰类的成员。具体作用如下:类的静态成员独立与对象而存在,即便没有对象(类的实例),静态成员依然存在。可以这么想,类的静态成员本质上跟类没啥关系,只是包装在类的作用域下,可能有语义的关联。
Q:说说C++和C的区别?
A:C++ = C + Object-Oriented C + Template + STL.
Q:说说C++中四种强制转换?
A:static_cast<target type>(variable)可以将变量强制转化为目标类型;const_cast<type>(variable)可以给变量底层强制加上/抹除const属性;dynamic_cast<type>(variable)可以做运行时转换,其中一个用处就是在语义正确的前提下,将父类对象的指针或引用转换成子类对象的指针或引用;reinterpret_cast<type>(variable)没了解过,据说很危险,不到万不得已千万别用。
Q:怎么判断一个数是二的倍数,怎么求一个数中有几个1,说一下你的思路并手写代码?
A:(x & 1)可以判断奇偶,(x & x-1)可以去掉二进制最低位的1. (c.f. 我的另一篇文章”a collection of coding problems”).
操作系统
摘自《程序员面试白皮书》
进程vs.线程
进程(process)与线程(thread)最大的区别是进程拥有自己的地址空间,某进程内的线程对于其他的进程不可见,即进程A不能通过传地址的方式直接读写进程B的存储区域。进程之间的通信需要通过进程间通信(Inter-process communication, IPC)。与之相对的,同一进程的各线程间可以直接通过传递地址或全局变量的方式传递信息。
此外,进程作为操作系统中拥有资源和独立调度的基本单位,可以拥有多个线程。通常操作系统中运行的一个程序就对应一个进程。在同一进程中,线程的切换不会引起进程切换。在不同的进程中进行线程切换,若从一个进程内的线程切换到另一个进程中的线程时,会引起进程切换。相比进程切换,线程切换的开销要小很多。线程与进程相结合能够提高系统的运行效率。
线程可以分为两类:
一类是用户级线程(user level thread)。对于这类线程,有关线程管理的所有工作都由应用程序完成,内核意识不到线程的存在。在应用程序启动后,操作系统分配给该程序一个进程号,以及其对应的内存空间等资源。应用程序通常现在一个线程中运行,该线程被称为主线程。在其运行的某个时刻,可以通过调用线程库中的函数创建一个在相同进程中运行的新线程。用户级线程的好处是非常高效,不需要进入内核空间,但并发效率不高。
另一类是内核级线程(kernel level thread)。对于这类线程,有关线程管理的所有工作由内核完成,应用程序没有进行线程管理的代码,只能调用内核线程的接口。内核维护进程及其内部的每个线程,调度也有内核基于线程架构完成。内核级线程的好处是,内核可以将不同的线程更好地分配到不同的CPU,以实现真正的并行计算。
事实上,在现代操作系统中,往往使用组合方式实现多线程,即线程创建完全在用户空间中完成,并且一个应用程序中的多个用户级线程被映射到一些内核级线程上,相当于是一种折中方案。
上下文切换
对于单核单线程CPU而言,在某一时刻只能执行一条CPU指令。上下文切换(context switch)是一种将CPU资源从一个进程分配给另一个进程的机制。从用户角度看,计算机能够并行运行多个进程,这恰恰是操作系统通过快速上下文切换造成的结果。在切换的过程中,操作系统需要先存储当前进程的状态(包括内存空间的指针,当前执行完的指令等等),在读入下一个进程的状态,然后执行此进程。
系统调用
系统调用(system call)是程序向系统内核请求服务的方式。可以包括硬件相关的服务(访问硬盘等),或者创建进程,调度其他进程等。系统调用是程序和操作系统之间的重要接口。
Semaphore/Mutex
当用户创立了多个线程/进程时,如果不同线程/进程同时读写相同的内容,则可能造成读写错误,或者数据不一致。此时,需要通过加锁的方式,控制核心区域(critical section)的访问权限。对于semaphore而言,在初始化变量的时候可以控制允许多少个线程/进程同时访问一个critical section,其他的线程/进程会被堵塞,直到有人解锁。Mutex相当于只允许一个线程/进程访问的semaphore。此外,根据实际需要,人们还实现了一种读写锁(read-write lock),它允许同时存在多个reader,但任何时候之多只有一个writer,且不能和reader共存。
死锁
在引入锁的同时,我们遇到了一个新的问题:死锁(dead lock)。死锁是指两个或多个线程/进程之间相互阻塞,以至于任何一个都不能继续运行,因此也不能解锁其他线程/进程。例如,线程1占有锁A,并且尝试获取锁B;而线程2占有锁B,并尝试获取锁A。此时,两者相互阻塞,都无法继续运行。
总结产生死锁的四个条件(只有当四个条件同时满足时才会产生死锁):
- Mutual Exclusion — Only one process may use a resource at a time
- Hold-and-Wait — Process holds resource while waiting for another
- No Preemption — Can’t take a resouce away from a process
- Circular Wait — The waiting processes form a cycle
生产者消费者
生产者消费者模型是一种常见的通信模型:生产者和消费者共享一个数据管道,生产者将数据写入buffer,消费者从另一头读取数据。对于数据管道,需要考虑为空和溢出的情况。同时,通常还需要将这部份共享内存用mutex加锁。在只有一个生产者消费者的情况下,可以设计无锁队列(lockfree queue),线程安全地直接读写数据。
进程间通信
在介绍进程的时候,我们提起过不能直接读写另一个进程的数据。两者之间的通信需要通过进程间通信(inter-process communication,IPC)进行。进程通信的方式通常遵循生产者消费者模型,需要实现数据交换和同步两大功能。
- Shared-memory + semaphore: 不同进程通过读写操作系统中特殊的共享内存进行数据交换,进程之间用semaphore实现同步。
- Message passing: 进程在操作系统内部注册一个端口,并检测有没有数据,其他进程直接写数据到该端口。该通信方式更加接近与网络通信方式。事实上,网络通信也是一种IPC,知识进程分布在不同机器上而已。
网络
摘自《程序员面试白皮书》
网络分层
计算级之间的交互模型通常是指Open System Interconnection model (OSI), 该模型将网络通信系统抽象成了七层。因其不太实用,工业界普遍使用简化的TCP/IP五层模型。
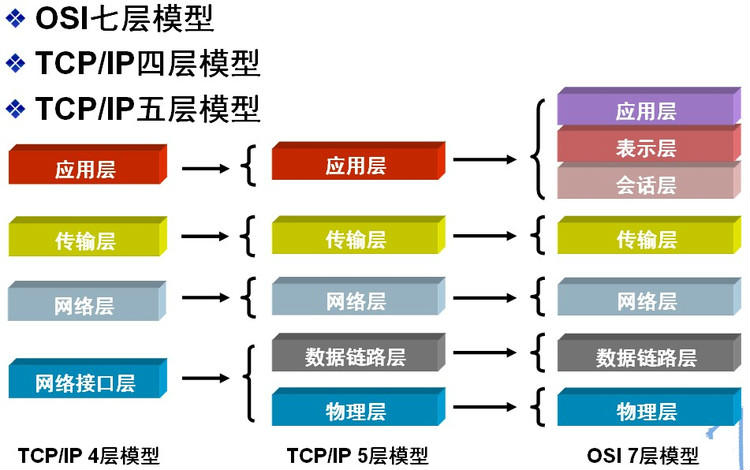
- 应用层 针对特定的协议,为应用程序做服务,比如SMP,POP3,SSH,FTP等协议。
- 表示层 负责数据格式的转换,把不同表现形式的信息转换成适合网络传输的格式。
- 会话层 负责建立和断开通信连接,什么时候建立连接,什么时候断开连接以及保持多久的连接。
- 传输层 在两个通信节点之间负责数据的传输,起着可靠传输的作用。(运行在这一层的设备有四层交换机,四层路由器)
- 网络层 路由选择,在多个网络之间转发数据包,负责将数据包传送到目的地址。(运行在这一层的设备有路由器,三层交换机)
- 数据链路层 负责物理层面互联设备之间的通信传输,比如一个以太网相连的两个节点之间的通信,是数据帧与1、0比特流之间的转换。(运行在这一层的设备是网桥、以太网交换机、网卡)
- 物理层 主要是1、0比特流与电子信号的高低电平之间的转换。(运行在这一层的设备是中继器、双绞线)
路由
从用户角度看,路由(routing)是指将数据从一个用户终端,通过网络节点(例如路由器、交换机等),发送到另一个用户节点的过程。理论上说,对于一个拥有多个节点的拓扑网络而言,路由是指在Network Layer(OSI model的第三层)将数据包(data packet)从一个节点以最优的路径发送到目标节点的实现方法。其核心包括:如何获得邻近节点的信息,如何估计链路质量,如何寻址,如何构建网络拓扑等等。通过路由器之间的路由协议(routing protocol)可以实现两个网络节点之间信息(包括网络域名,邻近节点,链路质量等)的交换和散布,通过不断重复该过程,每个节点都会获得足够多关于所在网络的拓扑信息。当有数据包需要传送时,路由器再通过路由算法(routing algorithm)计算传递当前数据包的最优路径,并把数据包发送给下一个邻近节点。许多路由算法基于图理论,实现了最小生成树,最短路径等等经典的拓扑算法。
网络中,所谓地址是指IP地址,IPv4规定利用32bits作为IP地址(即4bytes,也就是我们常看到的x.x.x.x,x在0-255之间,2^8-1=255)。但随着网络设备的增多,IPv4已经不能满足人们的需求,故互联网逐渐向IPv6进行演进,IPv6利用128bits作为IP地址。
事实上,直观而言,network routing的过程就相当于传统意义上的邮包寄送,IP地址可以类比于邮政编码,路由器就相当于邮局,通过目的地邮政编码与邮局系统中的递送路径进行比较,由此确定下一步应该把当前包裹传递到哪里。
网络统计指标
带宽/速率(Bandwidth/Rate)
所谓带宽是指一个网络节点能以多快的速度将数据接收/发送出去,单位时bits per second(bps)。对于实时性要求不高的数据,例如下载等,带宽时影响用户体验的主要因素。两个终端节点之间的带宽由路径中所有节点的最小带宽决定。同时,重算的数据发送速度不应超过当前的上载带宽,否则会对网络造成压力导致拥塞(congestion)。
One-way Delay/Round Trip Time
One-way Delay用以衡量网络的延迟。假设在时间点A从一个节点发送数据到另一个节点,目的节点在时间B收到数据,则两个时间点之差即为One-way Delay. 类似的,RTT则是数据完成一个Round Trip回到始发节点的时间差,一般RTT可以近似估计为One-way Delay的两倍。对于网络会议,IP电话等,延迟时影响用户体验的主要因素。延迟可能是由网络中某个节点处理数据速度慢,突然有大规模数据需要传输,或者某条链路不断重传数据造成的。延迟与带宽有一定的相关性,但没有必然联系。
TCP vs. UDP
在Transport Layer,数据流被分块传输。最常见的协议是TCP和UDP。
TCP
Reliable Protocol TCP(Transmission Control Protocol)是一种可靠的传输协议,在网络条件正常的情况下,TCP协议能够保证接收端收到所有数据,并且接受到的数据顺序与发送端一致。TCP通过在发送端给每个数据包分配单调递增的sequence number,以及在接收端发送ACK(acknowledgement)实现可靠传输。每个发送的数据包都包含序列号,当接收端收到数据包时,会发送ACK告诉发送端当前自己期待的下一个序列号是多少。例如,发送端分别发送了序列号为99、100、101、102的四个数据包,接收端收到数据包99后,会发送ACK 100,意味着接收端期待下一个数据包编号100. 如果由于某些原因,数据包100没有到达接收端,但数据包101、102到达了,那么接收端会继续发送ACK 100. 当发送端发现当前发送的数据包编号超过了100,但接收端仍然期望收到100,那么发送端就会重新发送数据包100. 如果接收端收到了重新发送的数据包100,那么接收端会回复ACK 103,继续进行剩下的数据传输,并且把数据包99、100、101、102按顺序传递给上一层。
Flow Control TCP使用了end-toend flow control以避免发送端发送数据过快导致接收端无法处理。TCP采用了滑动窗口(sliding window)实现流量控制。 接收端通过ACK告诉发送端自己还能接收多少数据,发送端不能发送超过该值的数据量。当接收端返回的窗口大小为0时,发送端停止发送数据,直到窗口大小被更新。由于ACK是由发送端发送的数据触发,可能接收端窗口已经打开,但是由于发送端已经停止发送,故接收端没有机会通过ACK告知发送端新的窗口大小,在这种情况下会造成死锁。在实际实现中,发送端会设置一个timer,如果timer到期,发送端会尝试发送小数据包,以触发接收端ACK.
Congestion Control 为了控制传输速度防止堵塞网络,并且在网络容量允许的范围内尽可能多的传输数据,TCP引入congestion control,用以判断当前的网络负荷,并且调整传输速率。TCP通常采用additive increase, multiplicative decrease的算法,即如果按时收到对应的ACK,则下一次传输速率线性增加,否则视为发生了网络拥塞,下一次传输的比特数折半。所谓的“按时”基于RTT:发送端会估计RTT,并且期望当数据包发送以后,在RTT时间内收到对应的ACK。现在TCP需要分别实现slow-start,congestion avoidance,fast retransmit和fast-recovery,以达到最高的效率。
UDP
相比与TCP,UDP(User Datagram Protocol)简单许多:连接建立时不需要经过类似于TCP的三次握手,只需要知道接收端的IP和端口,发送端就可以直接发送数据。同时,UDP也没有ACK,flow control和congestion control,故UDP相较TCP传输更快,使用起来更简单。

